





監視ツールをNew RelicからSite24x7へ:費用・機能・運用で比較したリアルな移行記録
目次
こんにちは、L小川です。最近は米粉を使ったお菓子作りにチャレンジしています。近くのスーパーでは米粉の種類が少ないのが悩ましいところです。
弊社では2014年頃から監視ツール New Relicを利用してきたのですが、2024年4月からSite24x7に移行しました。今回のブログでは、Site24x7に移行した経緯・移行にあたって工夫したこと・実際に使ってみてどうだったか、について書きたいと思います。
移行した理由
費用
目指すチームの姿との不整合
New Relicでは、すべての操作ができるFullユーザと、ダッシュボードの閲覧・作成ができるBasicユーザがあります。Basicユーザはいくつでも作成可能ですが、できることはダッシュボードの作成と閲覧のみです。そのため、Basicユーザでは監視ツールを使い倒して監視スキルを高めるということが期待できません。Fullユーザを増やすという選択肢も検討しましたが、費用の面から断念しました。監視・開発メンバーが同じものを見て議論し、知見を深め合うことがチームの姿として望ましいと考えており、このままでは目指すチームの姿に近づけないと感じていたことも移行を決めた理由のひとつです。
必要な機能
- サーバメトリクス監視(CPU, ディスク使用量, メモリ使用率, ロードアベレージ等)
- APM(Application Performance Monitoring)
- サービス死活監視
- フロントエンド監視
- ダッシュボード
なぜSite24x7を選んだのか
費用
DatadogやMackerelも候補として検討しましたが、我々のサーバ台数だとNew Relicの費用と大きく変わらず、Site24x7の場合は他のツールより最大30%程度安くなる試算となりました。
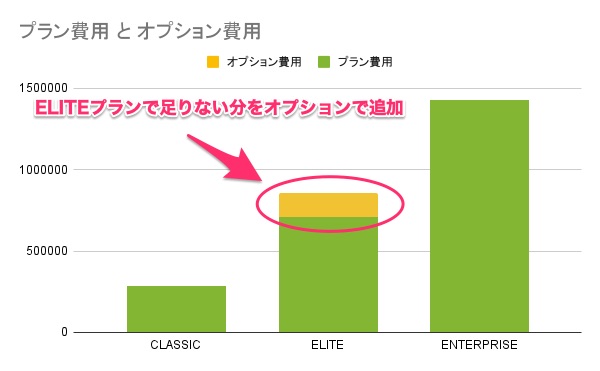
Site24x7で用意されている「CLASSIC」や「ELITE」などのプランで監視数が足りない場合は、オプションで必要な分だけ追加購入できるので、ムダのない料金設定ができます。
機能
Site24x7だけで先述の「必要な機能」を満たせるので、検証・導入の手間が最小限で済みます。
試用期間の長さ
試用期間は30日あり、監視運用フローの構築・検証をするのに十分な期間でした。試用期間内では、監視設定のほか、通知フローの構築、既存機能ではできないことの代替手段の検討など、実際の運用を想定するとやるべきことは多いです。試用期間が十分に長いことで余裕を持って検討を進められました。
また、サーバ運用保守業務の納品物として「サーバの各種メトリクスのグラフ」があるのですが、30日分のデータを使って既存のツールと同等のものが作れることも確認できました。
サポート
試用期間中でもサポートを受けることができ、監視通知フローの構築にあたっての不明点を解消しつつ、移行作業を進められました。
ドキュメントが多く用意されているので、基本的な操作で困ることは少なかったです。
Site24x7の導入にあたり工夫したこと
Site24x7での監視運用作業がやりやすくなるように行った工夫をいくつか紹介します。
監視の表示名(display_name)設定
EC2インスタンスのサーバ監視をする場合、デフォルトではサーバ監視一覧の画面に「ip-172-16-101-105.ap-northeast-1.compute.internal」のように表示されます。この表示だと、どのサービス・どの環境のサーバかがわからないので、Site24x7のインストール時にdisplay_name(-dn)を指定して、サービス名・環境を判別できるようにしました。
|
1 2 3 4 5 6 7 8 9 10 11 |
INSTANCE_ID=$(curl -s http://169.254.169.254/latest/meta-data/instance-id) yum -y install wget wget https://staticdownloads.site24x7.jp/server/Site24x7InstallScript.sh bash Site24x7InstallScript.sh \ -i -key={Site24x7アカウントのデバイスキー} \ -automation=true \ -dn={サービス名}-{環境名}-${INSTANCE_ID} \ -gn=SMOOSY.Cloud-EC2-staging \ -rule=SMOOSY.Cloud-staging |
 https://www.site24x7.jp/help/admin/adding-a-monitor/command-line-installation.html
https://www.site24x7.jp/help/admin/adding-a-monitor/command-line-installation.html
また、インストール時に「-rule=SMOOSY.Cloud-staging」とすることで、監視ルールを自動で設定しています。タグ付けやプロセス監視もこのルールで設定しています。
インスタンス定時終了時の自動監視削除
New Relicではインスタンスが正常終了した場合にはアラートとしないように設定できたのですが、Site24x7の場合は意図的な終了であっても”DOWN”として判定されます。
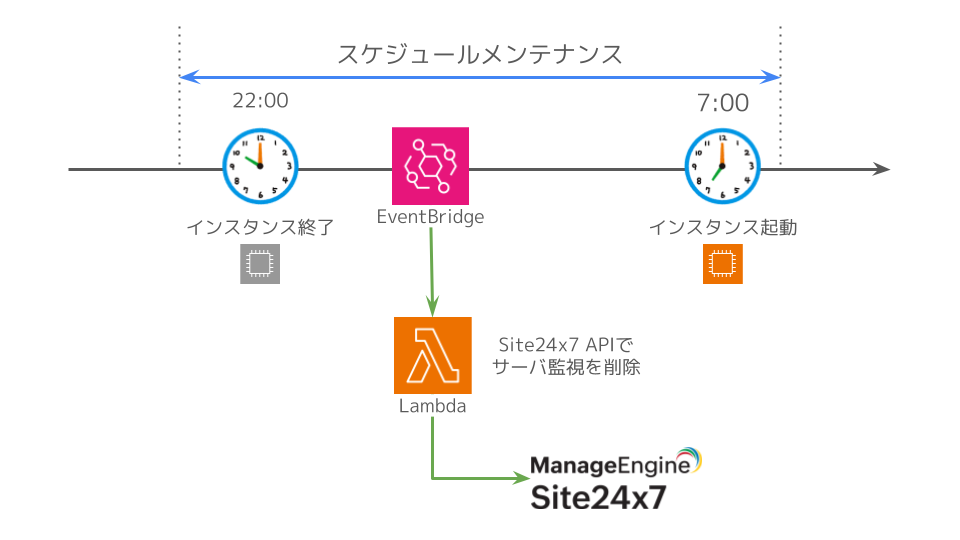
弊社の一部のステージング環境ではインスタンスを日次で起動・終了しており、Site24x7の場合はインスタンス終了のたびに”DOWN”の通知がSlackに届くことになります。そのため、「スケジュールメンテナンスの設定」と「Site24x7 APIを用いたサーバ監視削除Lambdaの実行」で、不要な通知がされないようにしています。
22:00でインスタンスが停止する場合、10分くらい前からスケジュールメンテナンスを設定します。その後、EventBridgeで起動したLambdaからSite24x7 APIを実行し、メンテナンス状態になったサーバ監視を削除します。
ミドルウェアのバージョン取得
New RelicにはInventoryという機能があり、サーバにインストールされているミドルウェアのバージョン情報が一覧で表示できます。脆弱性のあるミドルウェアがどのサーバにあるのかを調べる際に重宝していました。
Site24x7では同様の機能がないので、「IT自動化テンプレート」を使い、ミドルウェアのバージョン情報を取得しています。ミドルウェアのバージョン情報を取得するサーバコマンドやシェルスクリプトファイルを登録し、脆弱性の調査時に実行しています。


EC2インスタンスの場合、起動テンプレートで以下のスクリプトを作成しています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
#!/bin/bash HTTPD_IMAGE={HTTPDイメージ名}:{タグ} APP_IMAGE={アプリイメージ名}:{タグ} # httpdコンテナIDを取得 httpd_container_id=$(docker ps -qf "ancestor=\${HTTPD_IMAGE}") # httpdのバージョンを取得 httpd_version=$(docker exec ${httpd_container_id} httpd -v 2>&1 | head -n 1) if [ $? -eq 0 ]; then echo "httpd : ${httpd_version}" else echo "httpdのバージョンの取得に失敗しました" fi # アプリコンテナIDを取得 java_container_id=$(docker ps -qf "ancestor=\${APP_IMAGE}") # Javaのバージョンを取得 java_version=$(docker exec ${java_container_id} java -version 2>&1 | head -n 1) if [ $? -eq 0 ]; then echo "Java : ${java_version}" else echo "Javaのバージョンの取得に失敗しました" fi |
これから期待すること
New Relicのダッシュボードでは1つのウィジェットに複数サーバのメトリクスを表示できますが、Site24x7のダッシュボードでは1つのウィジェットに1つのサーバのメトリクスしか表示できません。
New Relicウィジェット
1つのウィジェットに複数サーバのメトリクスが表示可能。
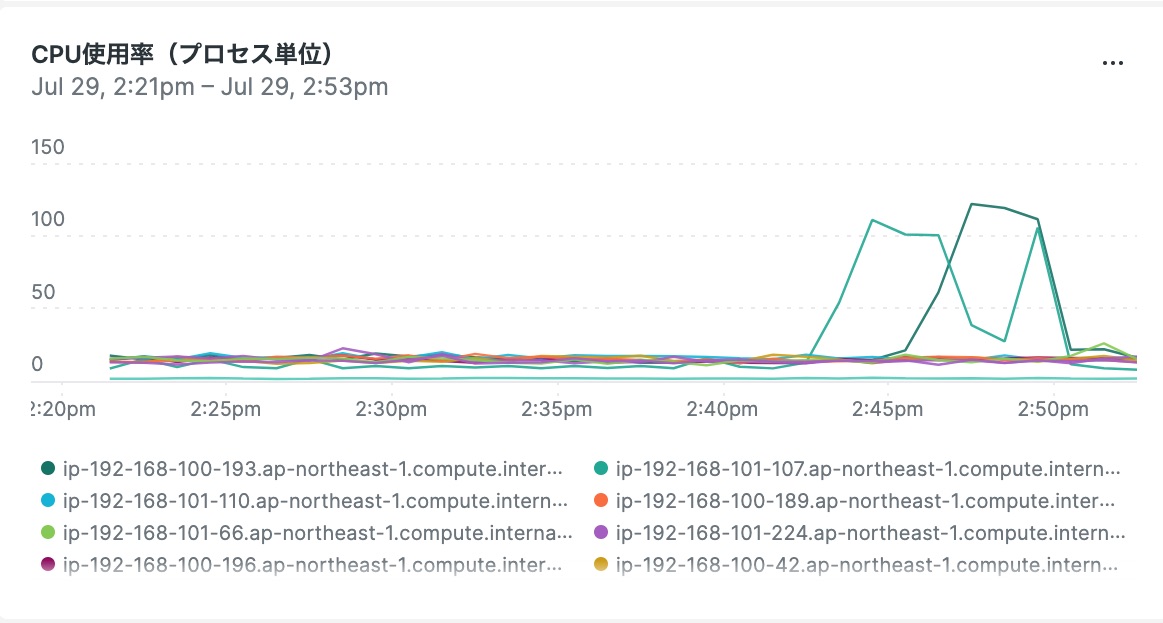
Site24x7ウィジェット
1ウィジェットにつき1サーバのメトリクスが表示される。

クラウド環境の運用作業では一度に複数サーバを差し替えることがあります。Site24x7のダッシュボードでは「メトリクスxサーバ台数分」のウィジェットを削除・追加する必要があり、これがなかなかの手間になっています。おそらくサーバを長く稼働する想定で設計されているかと思うのですが、今後の機能拡張に期待したいところです。
おわりに
現状Site24x7で大きなトラブルもなく監視作業ができています。ツールの移行では既存ツールとの違いが気になるところですが、監視スキルのあるエンジニアであればUIの違いにはすぐに適応できますし、細かい機能の差はSite24x7 APIやシェルスクリプトを利用することで補完できました。もし監視ツールでお悩みの方はSite24x7も候補に入れてみてはいかがでしょうか。
