





システム監視とエラーがあれば教えてくれるツール
目次
ディレクターの大神です。
今回は、システム運用でのシステム監視作業と弊社で使用しているエラーがあれば教えてくれるツールたちを紹介します。
システム監視作業も開発担当者の仕事に含まれますが、5分に1回ブラウザを開いて「Confit見れるかな?」って人が確認することはやっていません。(昔はやっていましたが)
現在のシステム監視は、下の図のように、BugsnagとNew Relicの監視サービスを使用して、監視作業を自動化しています。New RelicやBugsnagがエラーを検知すると、Slackに通知されるように設定して、すぐにエラーを検知できるようにしています。(下の図は、Confitの場合の例)
Slackで通知を受けて、よくない状況であれば、すぐ対応を始めます。エラーの対応のみ人が対応します。(当たり前ですが)
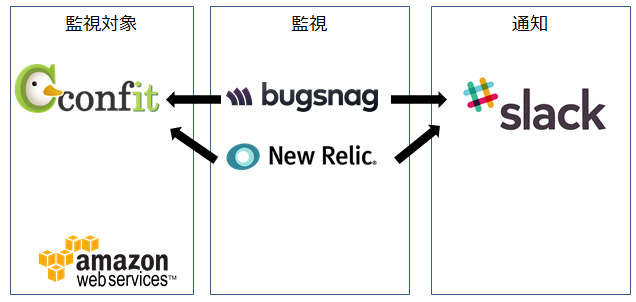
監視対象のサーバは、主にAmazon Web ServiceやさくらのVPSを使用しています。
サービス監視
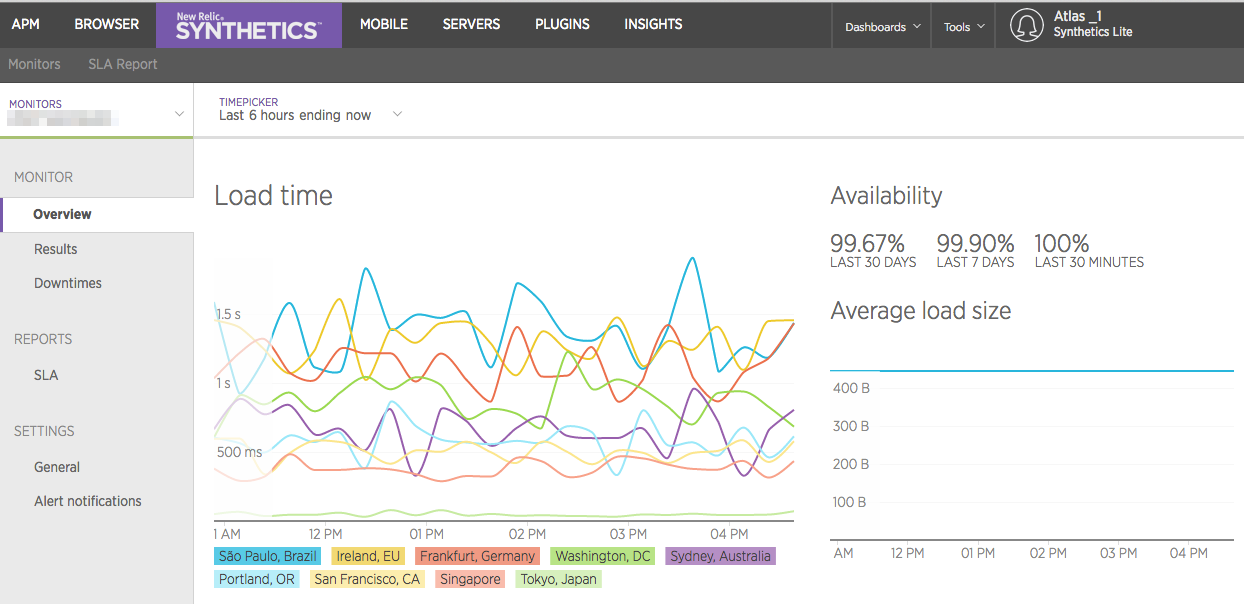
監視対象のサービスの特定のURLにアクセスして応答があることを確認します。アメリカ、ヨーロッパ、アジア、南米などの拠点からサービスを死活監視することで、特定の地域からアクセスできない、応答時間が遅い等を検知できるようにしています。
サービス監視には、特定の国からのアクセス状況も確認するためNewRelicのSYNTHETICSを使用しています。SYNTHETICSは、シンプルなPINGでの監視やブラウザでのJavaScriptの動作を含む監視もできます。PINGでの監視ならば、無料で利用することができます。
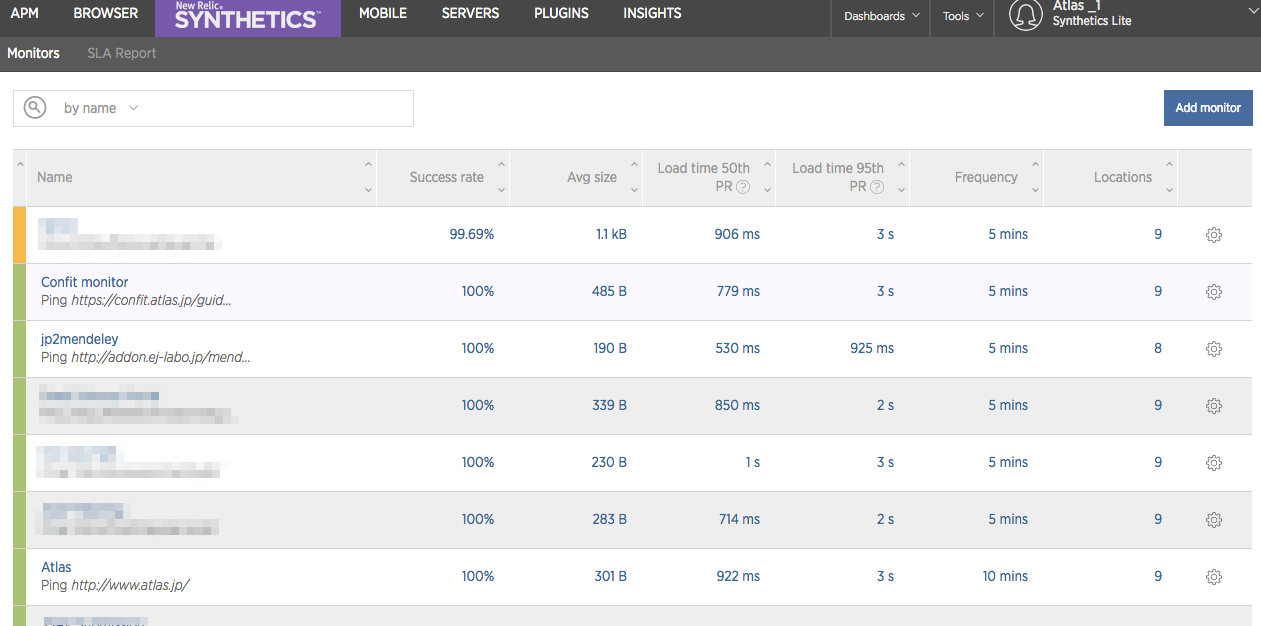
NewRelicのSYNTHETICSは、各監視対象のURLに各拠点から5分ごとにアクセスして、アクセスできない場合はすぐにメールで通知してくれます。(2015年1月末時点ではSlack通知は対応されていません)
リソース監視
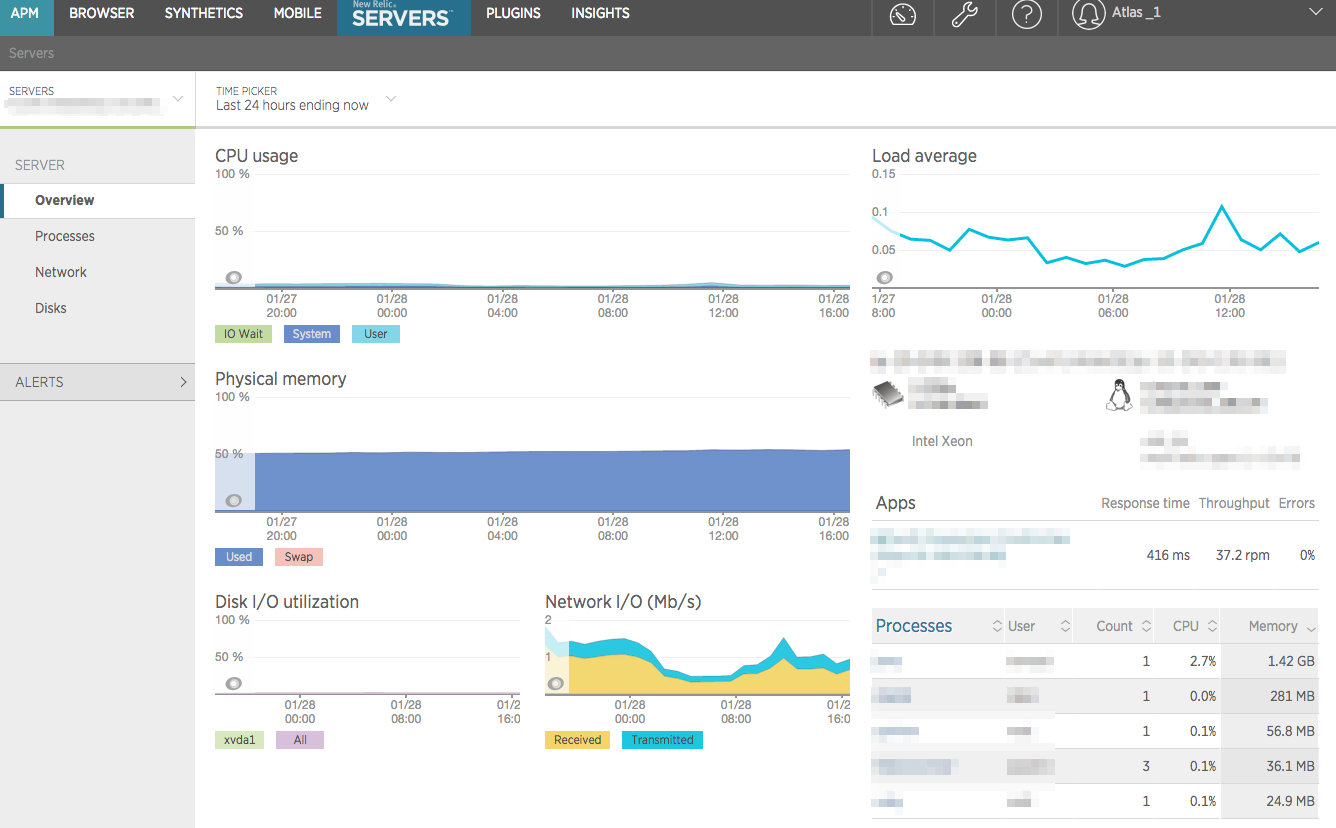
サーバーリソース(CPU, Disk, Memory, Network)の状況をモニタリング、閾値に近づいていたらアラート通知することで、異常事態に早く気付くことを目的としています。
このように、NewRelicの画面を見るとリソース使用状況を確認でき、この数値によって性能の良いサーバーに変更したり、サーバー台数を増やしたり等を調整するための指標としています。
監視設定として、NewRelicでサーバーの以下の項目に監視ポリシーを設定しておきます。(80%を超えると通知する等)
- CPU使用率
- メモリ使用率
- ディスク使用率
- ディスクIO
設定した値を超えると、このようにSlackで通知してくれます。
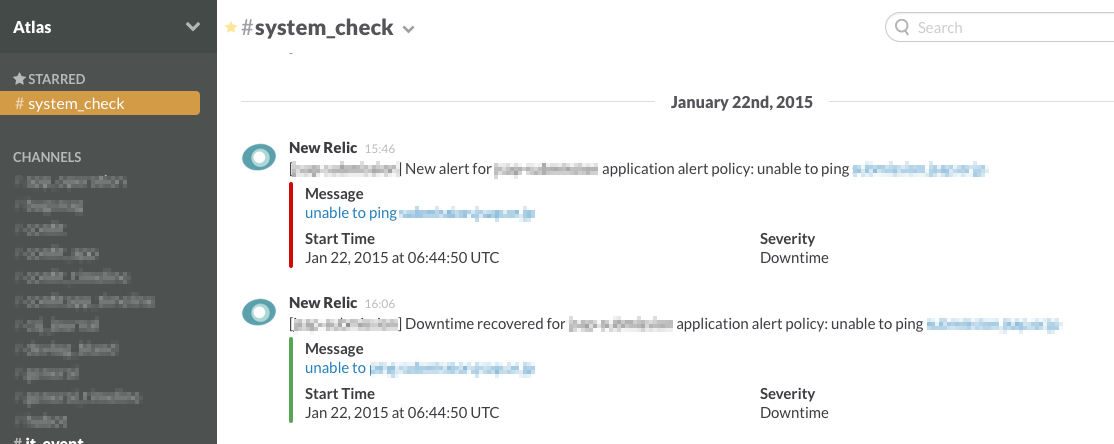
パフォーマンス監視
アプリケーションやデータベース等の性能を監視、パフォーマンス低下に気づき、改善していくことを目的とします。
- 応答時間が遅すぎないか
- サーバの応答時間(100ms以内を目安)
- ブラウザでの応答時間(1000ms以内を目安)
- エラー率が多すぎないか
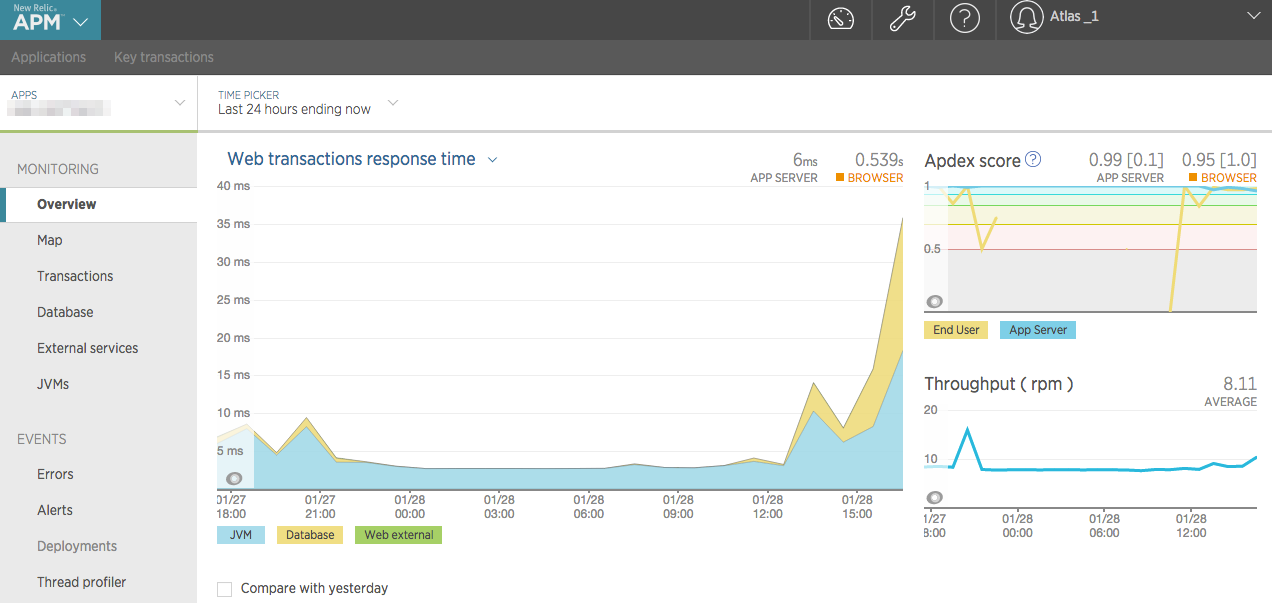
これも設定した値を超える場合は、Slackへ通知してくれます。
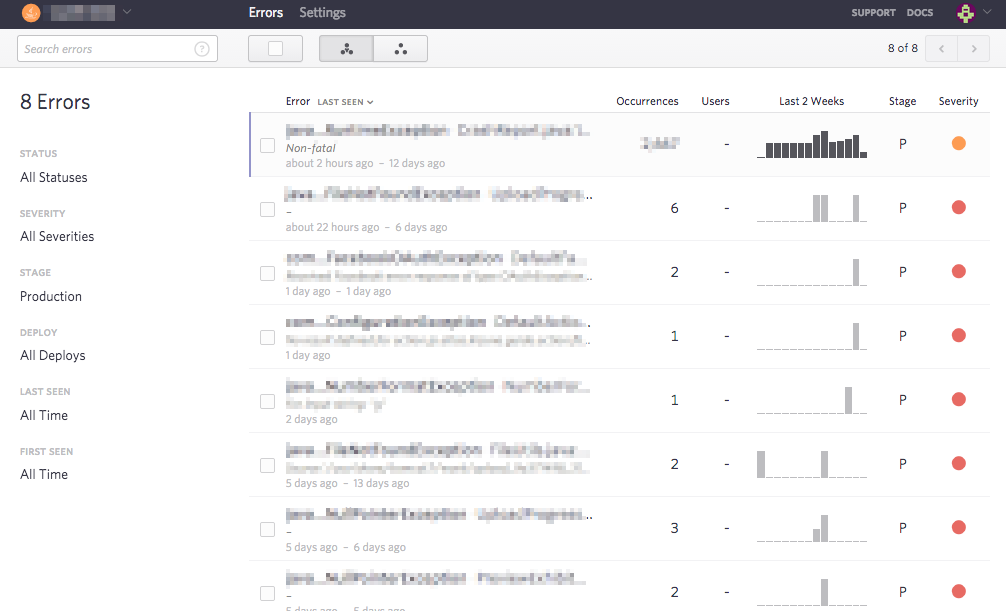
エラー監視
利用者の操作で発生したエラーに気づき、不具合を修正していくことを目的としてエラーを監視しています。
監視対象
- 本番環境(Production)
- ステージング(Staging)
- 開発環境(Development)
むすび
アトラスでは、Confitや論文検索Qross等のサービスの監視は、サービスを安定稼働させるだけでなく、サービスを安定稼働させつつも、サービス自身もを進化させていく方針としています。
新たに監視対象を追加していく際には、監視作業は自動化して、運用を開始するようにしています。昔からあるアトラスサービスや受託保守対象のシステムで自動化できていないサーバーもありますが、コツコツと対応していきます。
