





サーバ監視を支える5つのツール(NewRelic Logentries Bugsnag OpsGenie Slack)
目次
アトラスCTOの大神です。情報セキュリティ対策は世界的にも重要な経営課題であると認識されています。アトラスでも同様に重要課題として、様々な情報セキュリティに関する脅威のリスクについて日々対策しています。
情報セキュリティ方針を見直していく中で、サーバ監視・サービス監視プロセスを大きく見直し、監視プロセスや使用するツールも含めて監視プロセスを再設計しました。プロセスの変更から10ヶ月ほど経過し、安定して運用できるようになってきましたので、アトラスでのサーバ監視・サービス監視でのツールや仕組みの一部を紹介します。
サーバ監視は、顧客満足やサービス品質、情報セキュリティの観点からも重要な業務です。そのため、インシデントの発生前に検知して対策したり、インシデントが発生したら速やかに対応できる仕組み化が重要です。
仕組み化することで重要な作業にも無理なく対応できるように、監視ツールを組み合わせて、以下の方針でアトラスに合った仕組みを設計しました。
- サーバ監視は可能な限り自動化
- アラートの信頼性を高くする(オオカミ少年化しない)
- 全てのアラートの原因を特定・改善し、サービス自身も進化させる
- 必要な監視項目を網羅する
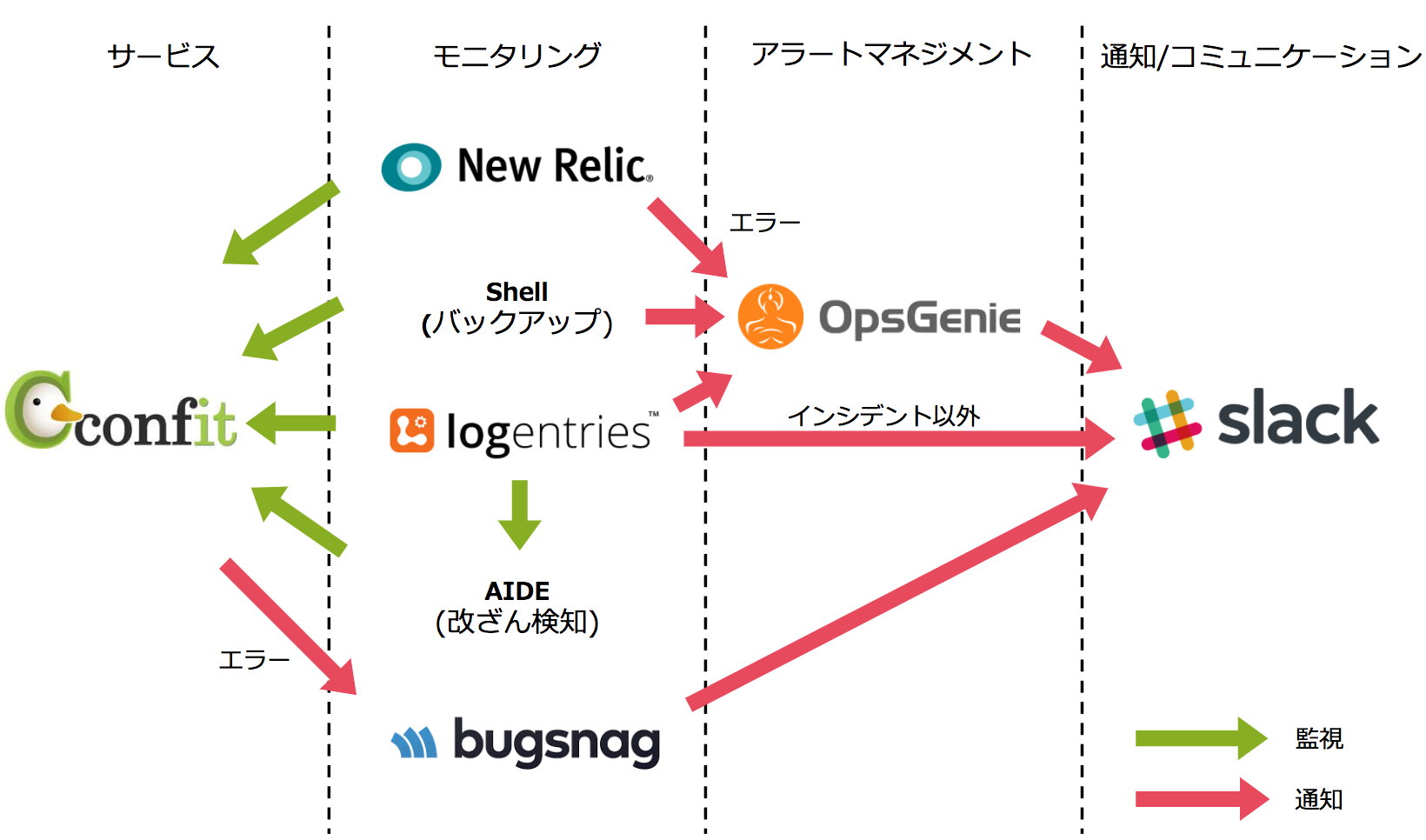
サーバ監視プロセスとツール
監視対象のサーバをモニタリングツールで監視し、異常があればアラートマネジメントツールを経由してコミュニケーションツールで監視担当者に通知します。
社内のコミュニケーションツールは以前からSlackを使用していますので、サーバ監視に関する全ての通知をSlackで集約して、漏れなく通知(アラート)を検知できるようにしています。
モニタリング
New Relic
NewRelicには複数の機能があり、監視項目ごとに機能を使い分けてサーバを監視するようにしています。
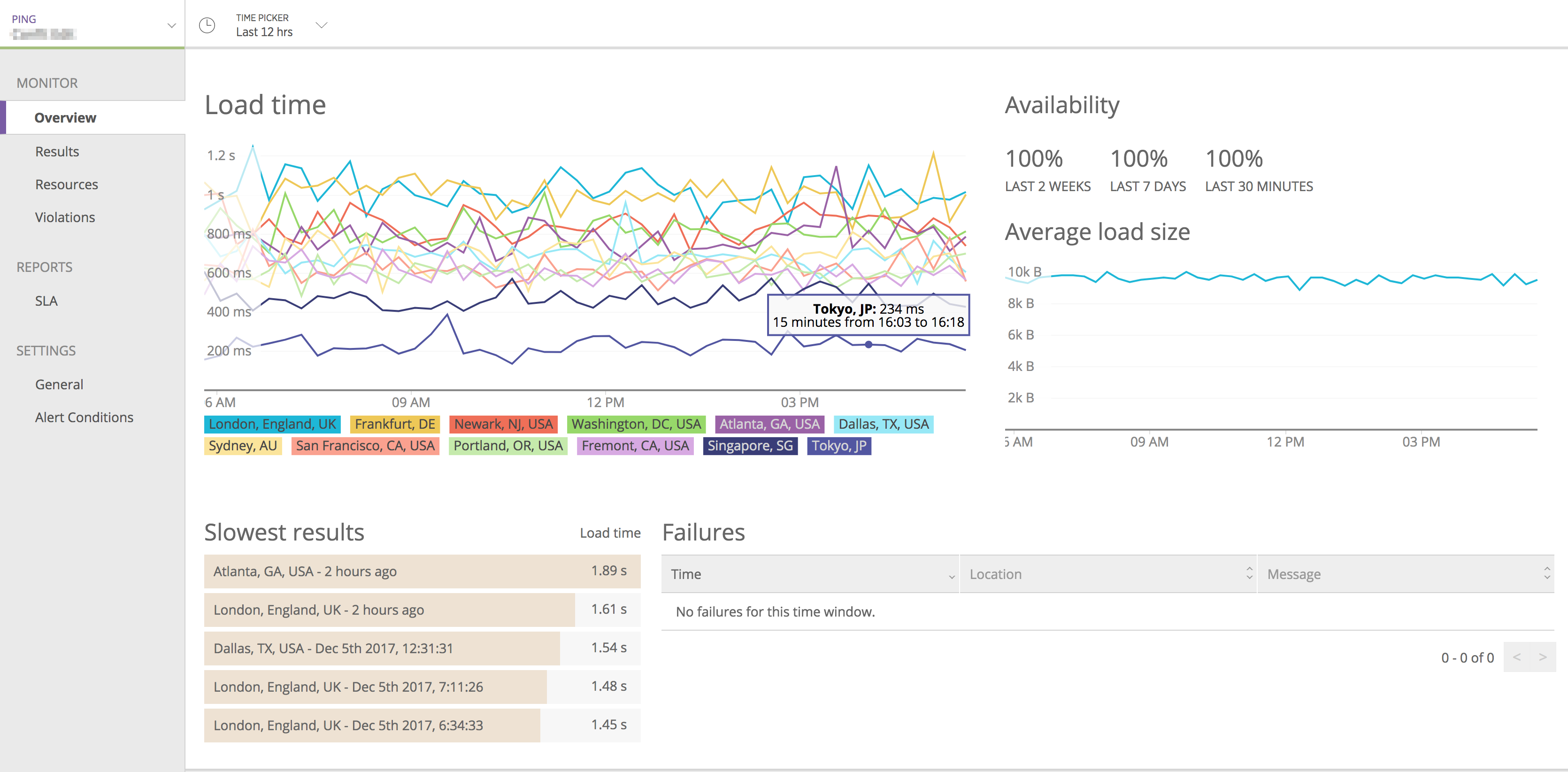
New Relic SYNTHETICS:死活監視
監視対象のサーバに他のネットワークからアクセスできることを監視します。東京、シンガポール、サンフランシスコ、ロンドンなど世界中の18箇所の拠点から死活監視ができるので、特定の地域からアクセスできないなども検知できます。
New Relic INFRASTRUCTURE:キャパシティ監視
現在または将来、サーバリソースが過不足なく稼働し続けられるかを監視します。サーバリソースが不足するようであればサーバを増強したり、ディスクを増設したりし、反対に全く使用していないようであればサーバの性能を下げてコストを削減するようにします。
サーバに専用エージェントをインストールし、サーバのCPUやロードアベレージなどの情報をNew Relicに収集して可視化します。以下のようにしきい値を設定して、この数値を超える場合にアラートを通知するようにします。(しきい値は実際の値ではありません)
- CPU使用率:100%が30分間
- メモリ使用率:90%が10分間
- ディスク使用率:80%が10分間
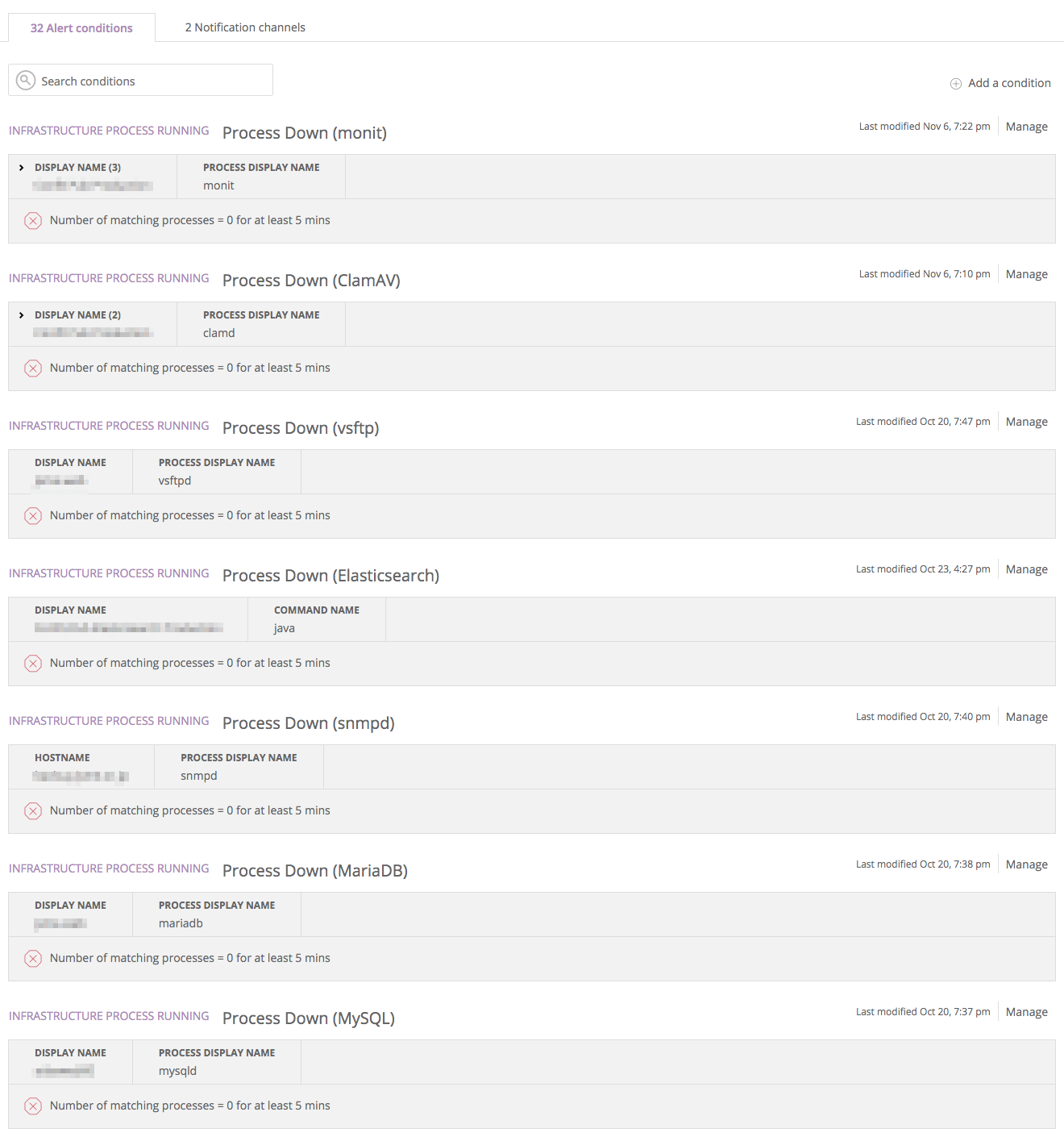
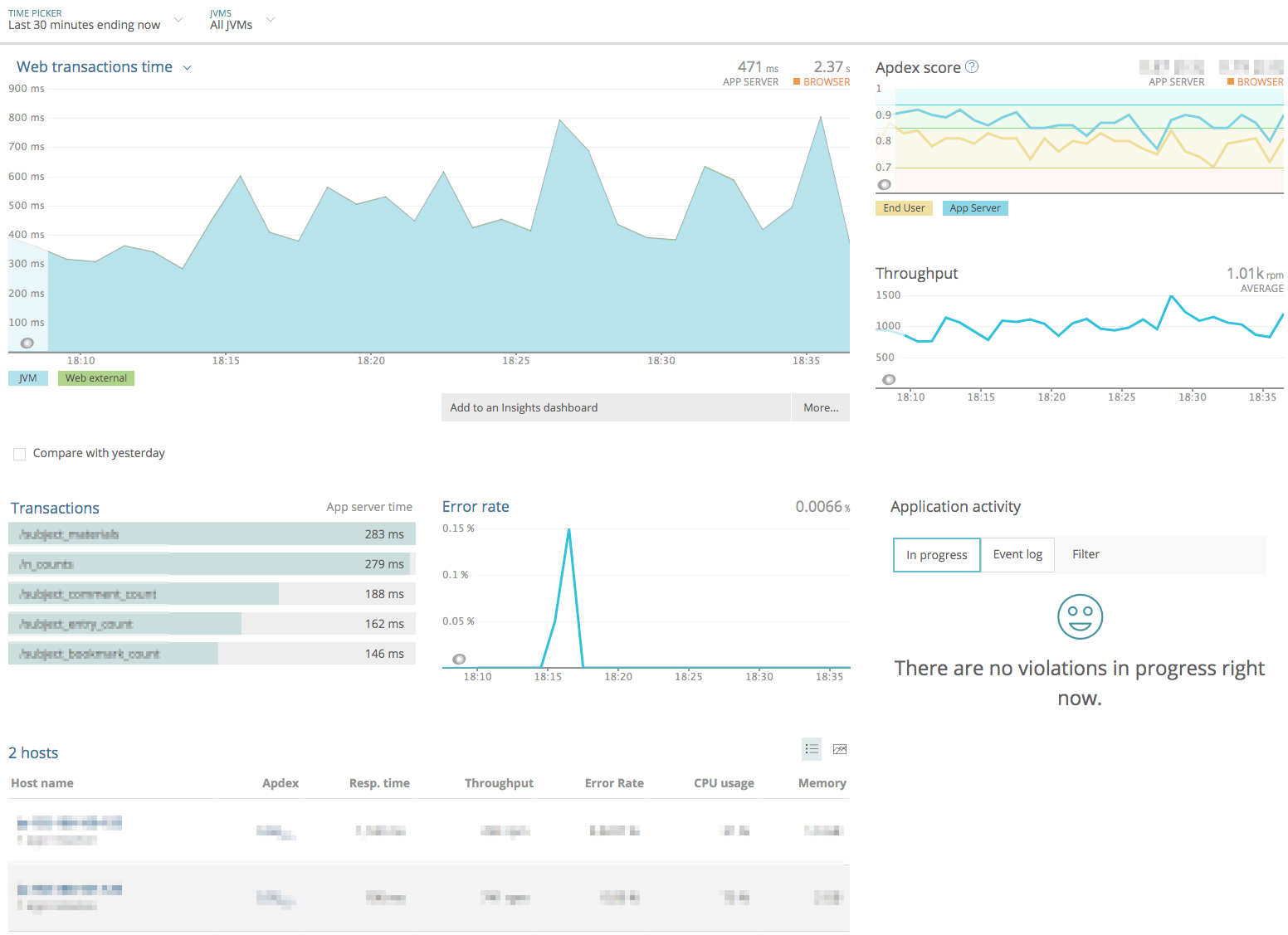
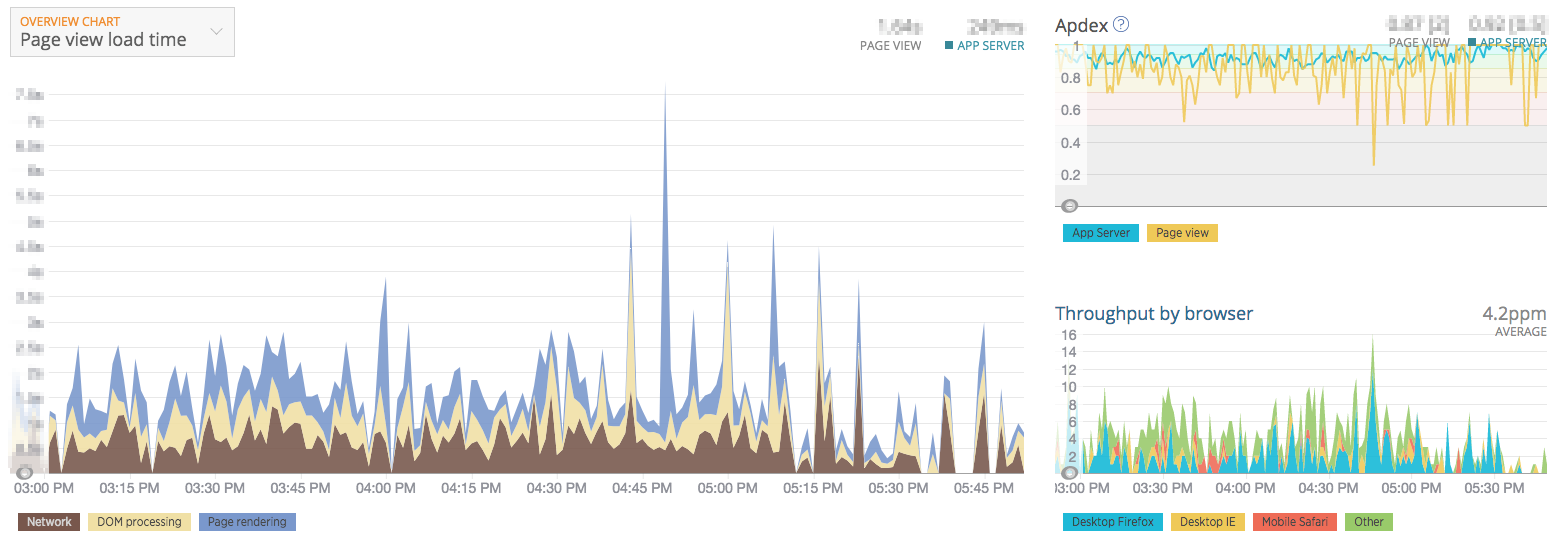
サーバが正しく動作するために必要なプロセス(WEBサーバやデータベースなど)が稼動していることを監視します。プロセス監視で停止したプロセスを検知すると状況の把握のためにアラートとして通知しますが、Monit(サーバ内でプロセスを監視して、停止したら自動起動してくれるツール)を使用して停止したプロセスを自動起動させ、早急にサービスを復旧できるようにしています。 サーバの応答時間(WEBサイトを表示するためにサーバが処理する時間)が事前に設定した時間を超えていないかを監視します。サービスのアプリケーションにNew Relicライブラリを組み込んで使用します。アプリケーションのサーバサイドのパフォーマンス情報を収集して可視化します。以下のようにしきい値を設定して、この数値を超える場合にアラートを通知するようにしています。(しきい値は実際の値ではありません) パフォーマンスが低下している場合はサーバ台数を増やすことで一時的に対応します。APMはアプリケーションのボトルネックになっている処理を検出できるので、継続的にアプリケーションの性能を改善できます。 ユーザーのブラウザでの応答時間(ユーザーがリンクをクリックしてページが表示されるまでの時間)が事前に設定した時間を超えていないかを監視します。アプリケーションにビーコンを設置し(Google Analyticsのようにアプリケーションが出力するHTMLに専用のJavaScriptを埋め込むタイプ)、パフォーマンス情報を収集して可視化します。以下のようにしきい値を設定して、この数値を超える場合にアラートを通知するようにしています。(しきい値は実際の値ではありません) サーバに専用エージェントをインストールすることで、サーバ内の任意のログファイル内のエラーを検知したり、ログファイルに出力される特定のキーワードを検出したりして、通知してくれるサービスです。 Logentriesではログファイルを監視することで各種監視を行っています。 ユーザー操作で発生したエラーを検知します。 本運用環境で発生するエラーは試験では想定できない事象もあるので、継続的にエラーに対応していくことが信頼性向上には重要です。検知したエラーは緊急であれば即日対応し、そうでないものはバージョンアップ時に対応します。 初めて発生したエラーはGitHubに自動的にIssue登録しているので、発生したエラーは漏れなく対応できます。 <h2アラートマネジメント
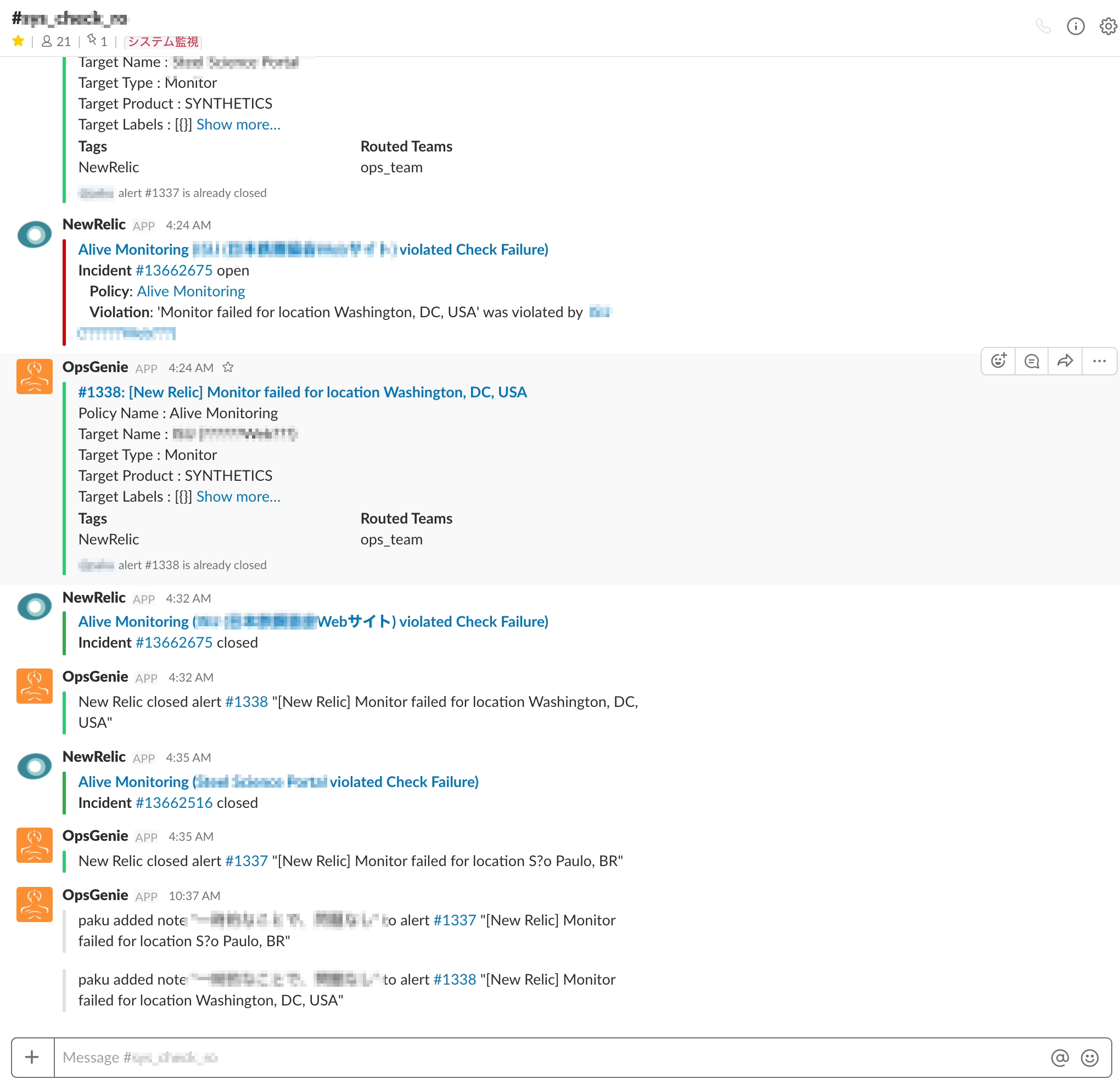
NewRelicやLogentriesからのアラートを一元管理するために使用します。アラートが100件以上通知されるような場合(モニタリングツールのアラート精度調整時)にも、重要な通知を漏れなく確認することを目的としています。また、監視チームに通知してから一定時間反応がない場合は、エスカレーションして異なる通知先に通知したり、電話してくれたりもするようです。(試行期間中に1度だけ電話をかけてもらいましたが、現在は使っていません) Slackは多くの企業で導入されているグループコミュニケーションツールです。Slackの監視用のチャンネルにOpsGenieで受け取ったアラートを通知します。通知の振り分けはOpsGenieが担当します。この通知を受けて担当者が対応します。 細かな監視設定は他にもありますが、アトラスではこれらのツールを使用してサーバ監視をしています。監視プロセスの再設計にあたり、ツールの選定候補には非常に素晴らしいサービスが多くあった印象です。それらのサービスの恩恵を受け、アトラスでは学術界のサービス開発に専念して、ConfitやSMOOSYなどのサービスを発展させています。 またサーバ監視以外にも、システム開発での情報セキュリティや情報資産を保護するための情報セキュリティの取り組みも進化させています。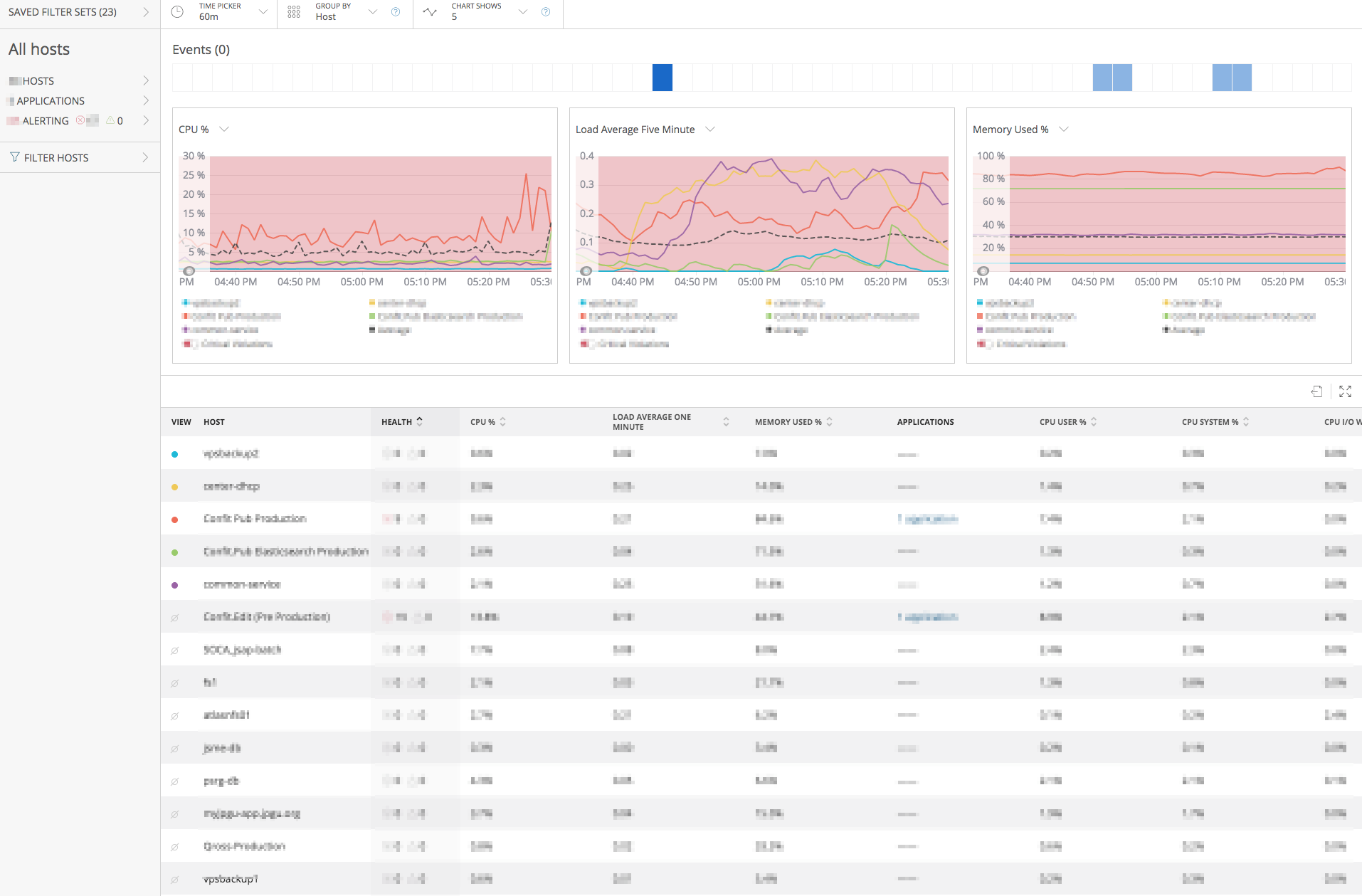
New Relic APM:パフォーマンス監視(サーバ)
New Relic BROWSER:パフォーマンス監視(クライアント)
Logentries
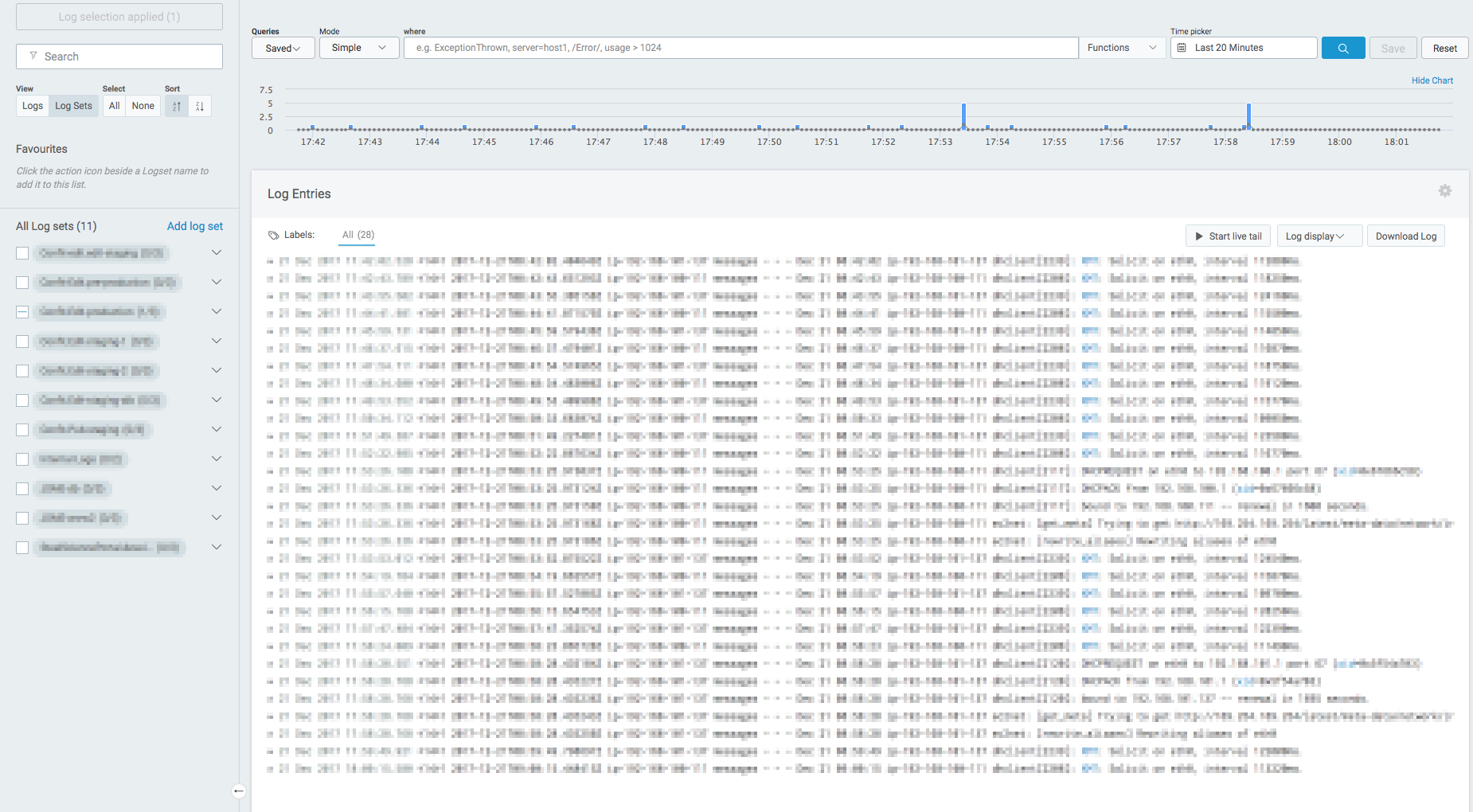
バッチジョブ監視、セキュリティ監視、バックアップ監視
Bugsnag
エラー監視
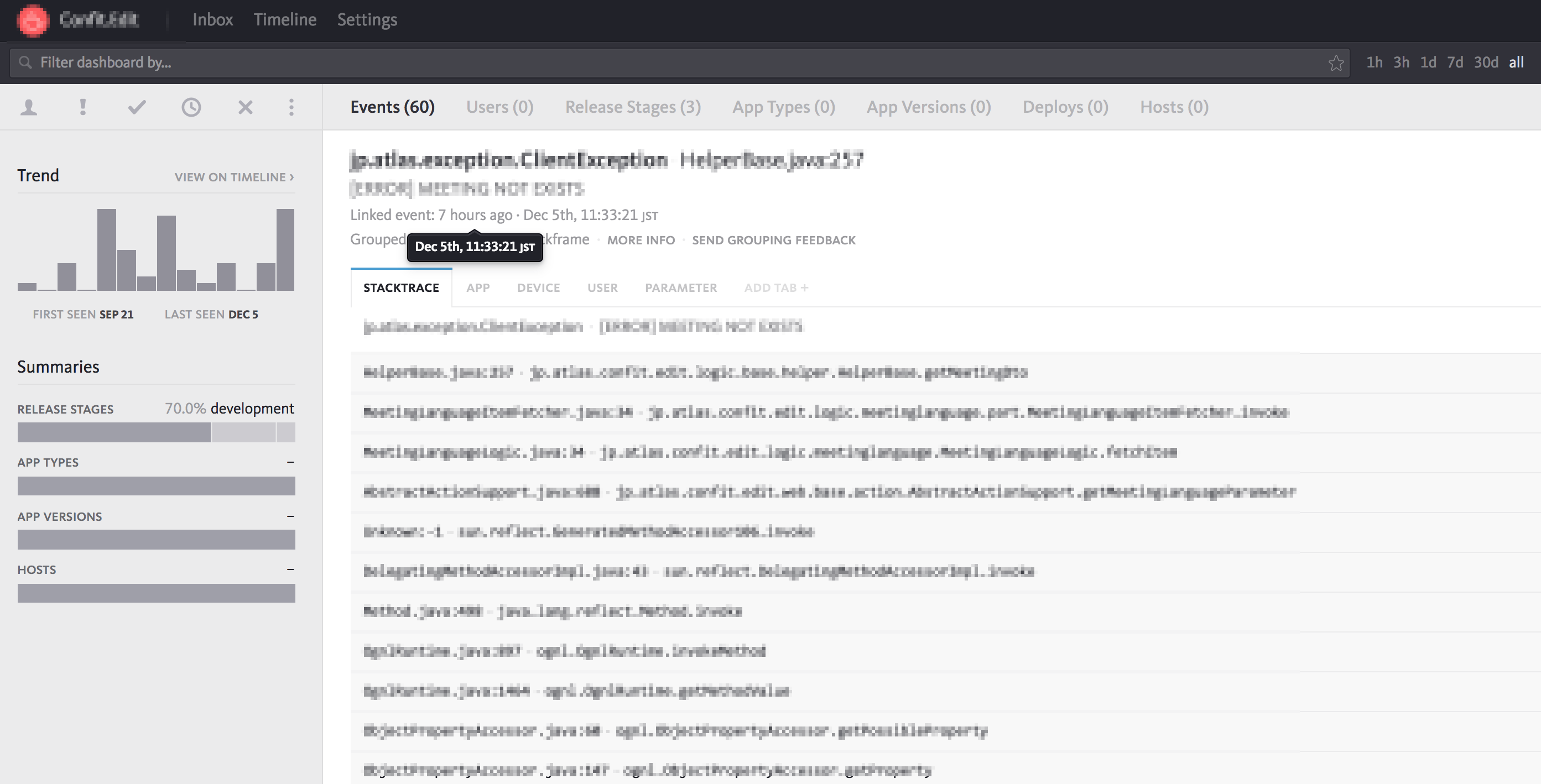
OpsGenie
通知/コミュニケーション
Slack
終わりに
